14 项目问题汇总
本文内容¶
踩坑¶
做项目过程中,肯定会遇到形形色色、大大小小的问题,但并不是所有问题都值得列出来探讨,这里仅列出个人认为有意义的问题。
具体的,包括大文件传输。
大文件传输¶
先看下之前的大文件传输,也就是游双书上的代码,发送数据只调用了writev函数,并对其返回值是否异常做了处理。
1bool http_conn::write()
2{
3 int temp=0;
4 int bytes_have_send=0;
5 int bytes_to_send=m_write_idx;
6 if(bytes_to_send==0)
7 {
8 modfd(m_epollfd,m_sockfd,EPOLLIN);
9 init();
10 return true;
11 }
12 while(1)
13 {
14 temp=writev(m_sockfd,m_iv,m_iv_count);
15 if(temp<=-1)
16 {
17 if(errno==EAGAIN)
18 {
19 modfd(m_epollfd,m_sockfd,EPOLLOUT);
20 return true;
21 }
22 unmap();
23 return false;
24 }
25 bytes_to_send-=temp;
26 bytes_have_send+=temp;
27 if(bytes_to_send<=bytes_have_send)
28 {
29 unmap();
30 if(m_linger)
31 {
32 init();
33 modfd(m_epollfd,m_sockfd,EPOLLIN);
34 return true;
35 }
36 else
37 {
38 modfd(m_epollfd,m_sockfd,EPOLLIN);
39 return false;
40 }
41 }
42 }
43}
在实际测试中发现,当请求小文件,也就是调用一次writev函数就可以将数据全部发送出去的时候,不会报错,此时不会再次进入while循环。
一旦请求服务器文件较大文件时,需要多次调用writev函数,便会出现问题,不是文件显示不全,就是无法显示。
对数据传输过程分析后,定位到writev的m_iv结构体成员有问题,每次传输后不会自动偏移文件指针和传输长度,还会按照原有指针和原有长度发送数据。
根据前面的基础API分析,我们知道writev以顺序iov[0],iov[1]至iov[iovcnt-1]从缓冲区中聚集输出数据。项目中,申请了2个iov,其中iov[0]为存储报文状态行的缓冲区,iov[1]指向资源文件指针。
对上述代码做了修改如下:
- 由于报文消息报头较小,第一次传输后,需要更新m_iv[1].iov_base和iov_len,m_iv[0].iov_len置成0,只传输文件,不用传输响应消息头
- 每次传输后都要更新下次传输的文件起始位置和长度
更新后,大文件传输得到了解决。
1bool http_conn::write()
2{
3 int temp = 0;
4
5 int newadd = 0;
6
7 if (bytes_to_send == 0)
8 {
9 modfd(m_epollfd, m_sockfd, EPOLLIN, m_TRIGMode);
10 init();
11 return true;
12 }
13
14 while (1)
15 {
16 temp = writev(m_sockfd, m_iv, m_iv_count);
17
18 if (temp >= 0)
19 {
20 bytes_have_send += temp;
21 newadd = bytes_have_send - m_write_idx;
22 }
23 else
24 {
25 if (errno == EAGAIN)
26 {
27 if (bytes_have_send >= m_iv[0].iov_len)
28 {
29 m_iv[0].iov_len = 0;
30 m_iv[1].iov_base = m_file_address + newadd;
31 m_iv[1].iov_len = bytes_to_send;
32 }
33 else
34 {
35 m_iv[0].iov_base = m_write_buf + bytes_have_send;
36 m_iv[0].iov_len = m_iv[0].iov_len - bytes_have_send;
37 }
38 modfd(m_epollfd, m_sockfd, EPOLLOUT, m_TRIGMode);
39 return true;
40 }
41 unmap();
42 return false;
43 }
44 bytes_to_send -= temp;
45 if (bytes_to_send <= 0)
46
47 {
48 unmap();
49 modfd(m_epollfd, m_sockfd, EPOLLIN, m_TRIGMode);
50
51 if (m_linger)
52 {
53 init();
54 return true;
55 }
56 else
57 {
58 return false;
59 }
60 }
61 }
62}
面试题¶
包括项目介绍,线程池相关,并发模型相关,HTTP报文解析相关,定时器相关,日志相关,压测相关,综合能力等。
项目介绍¶
- 为什么要做这样一个项目?
学习后端知识
- 介绍下你的项目
参考项目概述
线程池相关¶
- 手写线程池
参考threadpool.h
- 线程的同步机制有哪些?
互斥锁,信号量
- 线程池中的工作线程是一直等待吗?
不是,会一直从任务队列取任务来执行。
- 线程池工作线程处理完一个任务后的状态是什么?
释放该资源,等待执行下一任务
- 如果同时1000个客户端进行访问请求,线程数不多,怎么能及时响应处理每一个呢?
新来请求的要排队等着空闲线程处理,现在是固定线程池,最好的动态创建线程池
- 如果一个客户请求需要占用线程很久的时间,会不会影响接下来的客户请求呢,有什么好的策略呢?
会影响,使用异步的策略
并发模型相关¶
- 简单说一下服务器使用的并发模型?
同步io模拟proactor+threadpoll+epoll
- reactor、proactor、主从reactor模型的区别?
主要就是主线程是否处理读写的问题
- 你用了epoll,说一下为什么用epoll,还有其他复用方式吗?区别是什么?
epoll poll select
HTTP报文解析相关¶
- 用了状态机啊,为什么要用状态机?
一种设计模式,简化代码流程
- 状态机的转移图画一下
参考http连接的内容
- https协议为什么安全?
http+tls/ssl
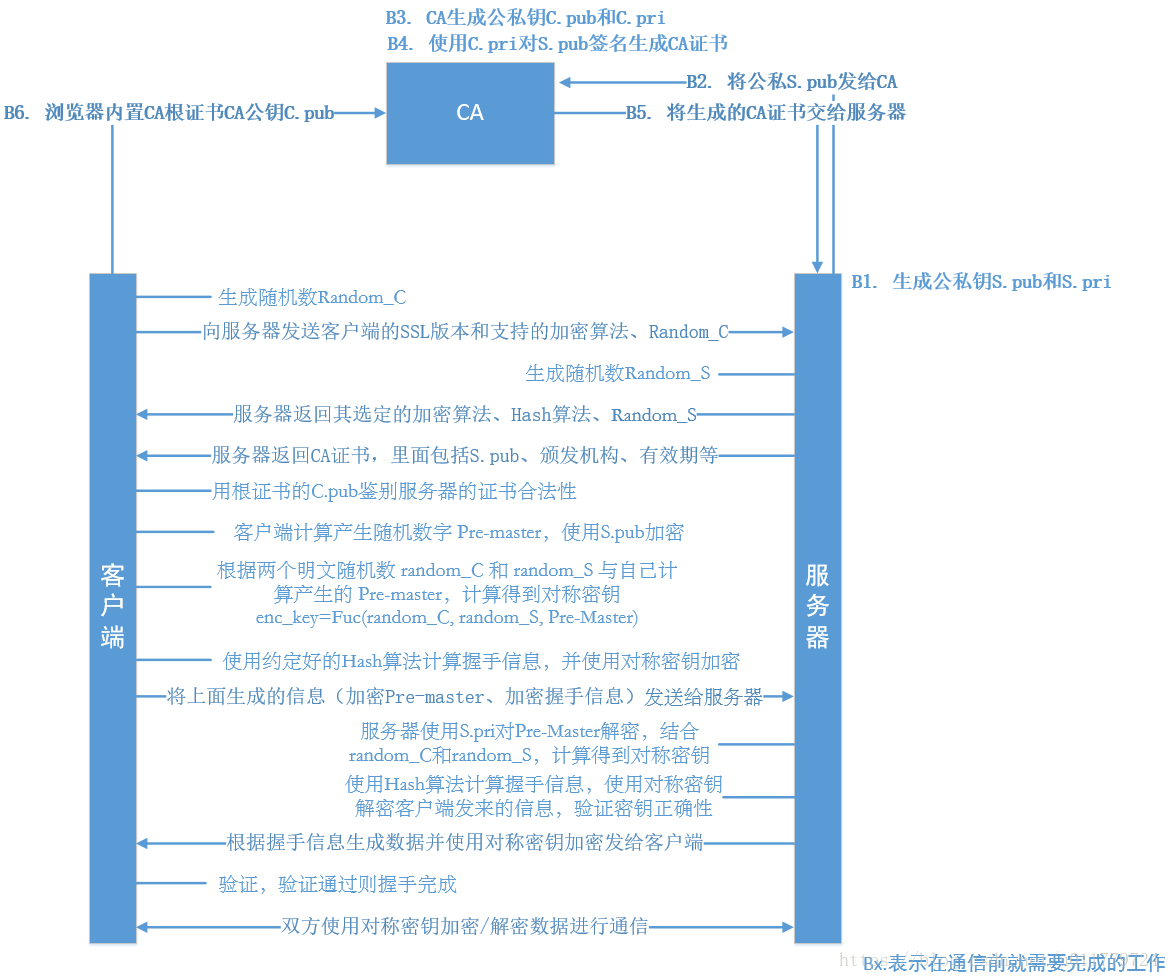
- https的ssl连接过程
- 客户端提交https请求
- 服务器响应客户,并把证书公钥发给客户端
- 客户端验证证书公钥的有效性
- 有效后,会生成一个会话密钥
- 用证书公钥加密这个会话密钥后,发送给服务器
- 服务器收到公钥加密的会话密钥后,用私钥解密,回去会话密钥
- 客户端与服务器双方利用这个会话密钥加密要传输的数据进行通信
- GET和POST的区别
GET和POST本质上就是TCP链接
数据库登录注册相关¶
- 登录说一下?
- 你这个保存状态了吗?如果要保存,你会怎么做?(cookie和session)
- 登录中的用户名和密码你是load到本地,然后使用map匹配的,如果有10亿数据,即使load到本地后hash,也是很耗时的,你要怎么优化?
- 用的mysql啊,redis了解吗?用过吗?
定时器相关¶
- 为什么要用定时器?
提高服务器性能,关闭非活动连接
- 说一下定时器的工作原理
双向链表
- 双向链表啊,删除和添加的时间复杂度说一下?还可以优化吗?
O(n),可以优化成时间轮,时间堆
- 最小堆优化?说一下时间复杂度和工作原理
最小堆的时间复杂度,堆排序原理
日志相关¶
- 说下你的日志系统的运行机制?
分为同步和异步
- 为什么要异步?和同步的区别是什么?
打印日志时候是把打印任务放入内存队列后就直接返回,而具体打印日志是有日志系统的一个日志线程去队列里面获取然后执行。
- 现在你要监控一台服务器的状态,输出监控日志,请问如何将该日志分发到不同的机器上?(消息队列)
分布式日志监控->Logstash
压测相关¶
- 服务器并发量测试过吗?怎么测试的?
webbench
-
webbench是什么?介绍一下原理
-
主函数进行必要的准备工作,进入bench开始压测
- bench函数使用fork模拟出多个客户端,调用socket并发请求,每个子进程记录自己的访问数据,并切入管道
- 父进程从管道读取子进程的输出信息
- 使用alarm函数进行时间控制,到时间后会差生SIGALRM信号,调用信号处理函数使子进程停止
- 最后只留下父进程将所有子进程的输出数据汇总计算,输出到屏幕上。
其整体流程为:main——>对命令行进行参数解析——>调用build_request函数构建HTTP的“Get”请求头——>调用bench测试函数(其中子进程调用benchcore函数进行压力测试),之后主进程从管道读取消息,并输出到标准输出上即可。
- 测试的时候有没有遇到问题?
代码重新编译即可
综合能力¶
- 你的项目解决了哪些其他同类项目没有解决的问题?
同步io模拟proactor
- 说一下前端发送请求后,服务器处理的过程,中间涉及哪些协议?
- DNS解析
- TCP连接
- 发送HTTP请求
- 服务器处理请求并返回HTTP报文
- 浏览器解析渲染页面
- 连接结束